Compositional Interpretability
CompInterp uncovers the structure of neural representations, showing how simple features compose into complex behaviours. By unifying tensor and neural network paradigms, model weights and data are treated as a single modality. This compositional lens on design, analysis and control paves the way for inherently interpretable AI without compromising performance.
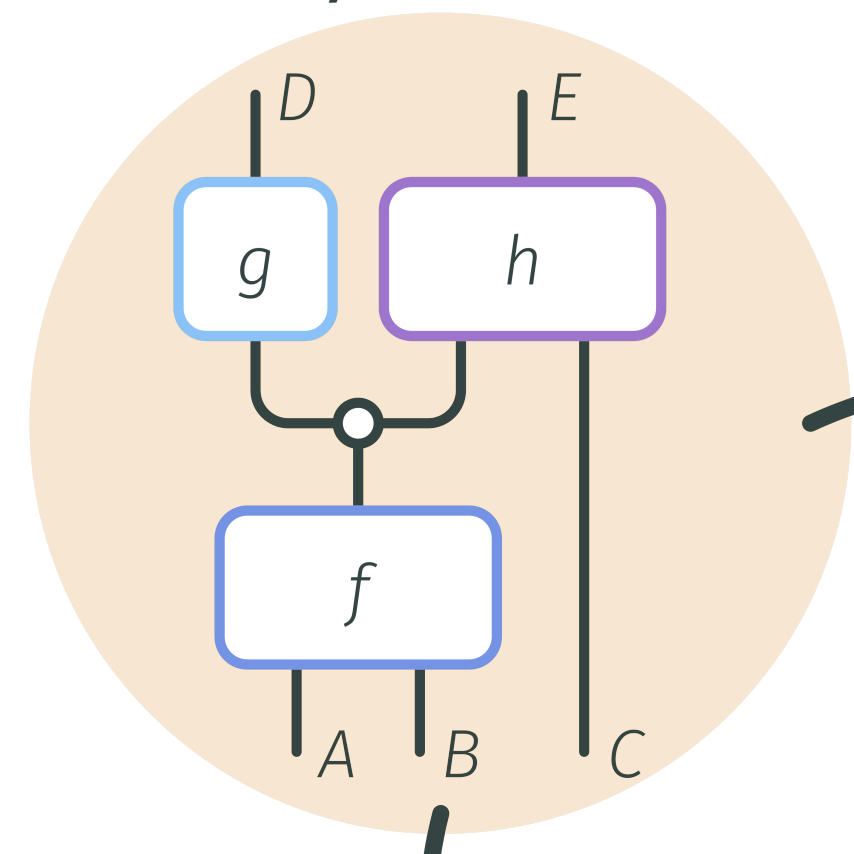
Compositional architectures capture rich non-linear (polynomial) relationships between representation spaces. Instead of masking them through linear approximations, CompInterp methods expose their inherent hierarchical structure accross levels of abstraction. This allows for weight-based subcircuit analysis, grounding interpretability in formal (de)compositions rather than post-hoc activation-based heuristics.
We’re now scaling compositional interpretability to transformers and CNNs by leveraging their low-rank structure through tensor decomposition and information theory. Learn more in our latest talk!
news
| May 12, 2026 | Explore our interactive manifold viewer on Qwen 3.5! |
|---|---|
| May 10, 2026 | Bilinear Autoencoders Find Interpretable Manifolds is out! |
| May 09, 2026 | From Mechanistic to Compositional Interpretability is out! |
| Apr 15, 2026 | We are mentoring for MARS (Mentorship for Alignment Research Students)! |
| Apr 14, 2026 | Research using our tools was featured in TIME magazine! |