publications
2026
- arXiv
 Bilinear autoencoders find interpretable manifoldsMay 2026
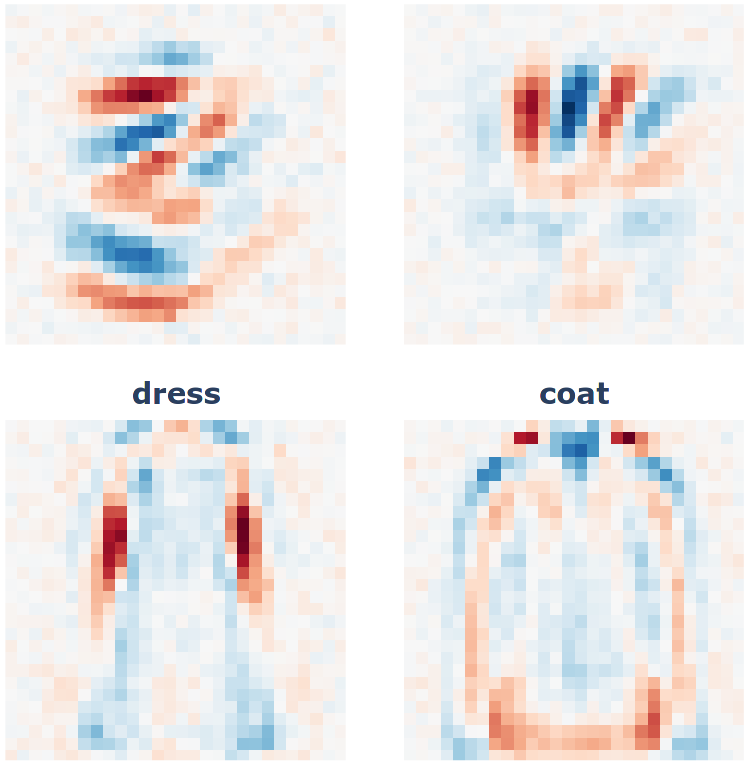
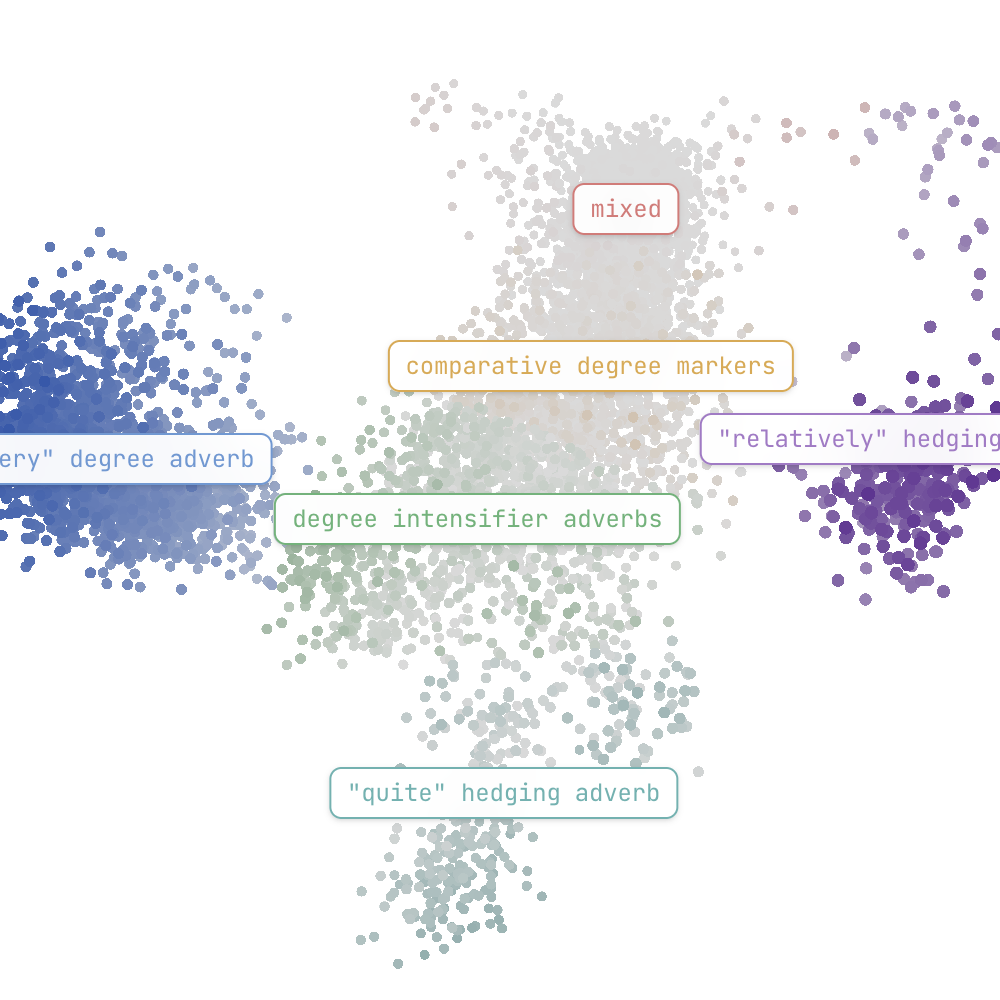
Bilinear autoencoders find interpretable manifoldsMay 2026Sparse autoencoders have become a standard tool for uncovering interpretable latent representations in neural networks. Yet salient concepts often span manifolds that current linear methods cannot capture without post hoc analysis. This paper uses quadratic latents to close this gap: we implement these with bilinear autoencoders, which decompose activations into low-rank quadratic forms, compose linearly in weight space, and admit input-independent geometric analysis. This qualitative difference in what concepts quadratic latents can detect challenges the standard linear representation hypothesis. Our experiments and visualisations show that multi-dimensional geometries are highly prevalent and that composite latents capture them well, systematically improving reconstruction error in language models. Furthermore, we show that autoencoders with varying geometric priors recover the same input subspace despite their dictionary entries being distinct. Practically, these models serve as an unsupervised tool for manifold discovery, which we demonstrate through an interactive online visualizer for Qwen 3.5. This is a step toward nonlinear but mathematically tractable latent representations whose composition is expressive and interpretable by design.
@misc{dooms_bilinear_2026, title = {Bilinear autoencoders find interpretable manifolds}, author = {Dooms, Thomas and Gauderis, Ward and Wiggins, Geraint and Oramas, Jose}, year = {2026}, month = may, eprint = {2605.08891}, archiveprefix = {arXiv}, primaryclass = {cs.LG}, url = {https://arxiv.org/abs/2605.08891}, } - arXiv
 From Mechanistic to Compositional InterpretabilityMay 2026
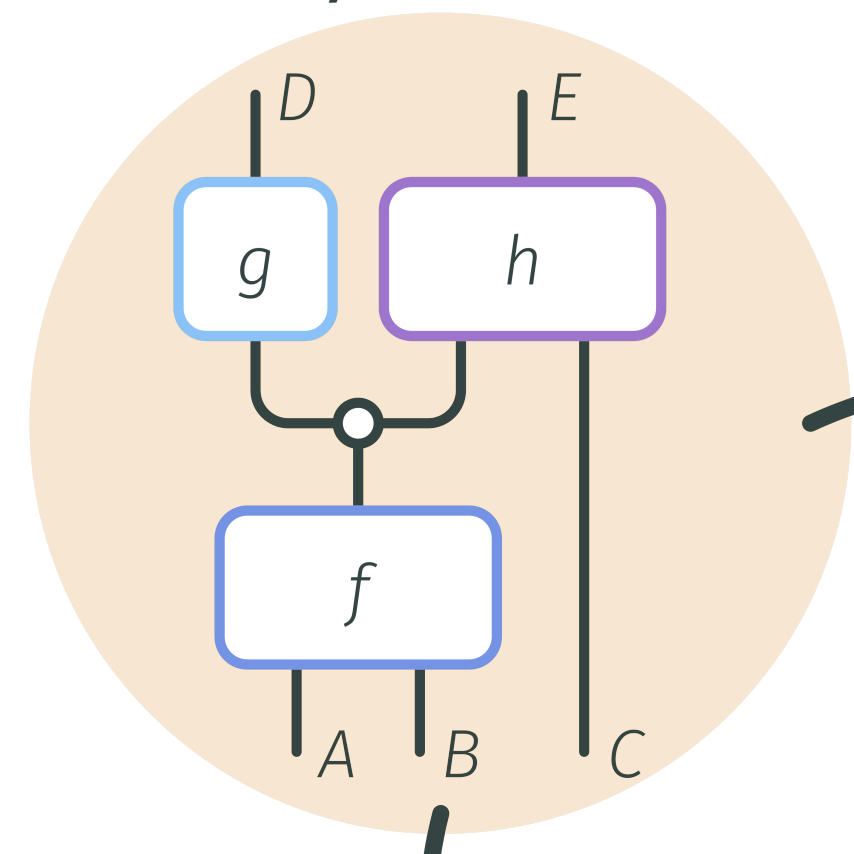
From Mechanistic to Compositional InterpretabilityMay 2026Mechanistic interpretability aims to explain neural model behaviour by reverse-engineering learned computational structure into human-understandable components. Without a formal framework, however, mechanistic explanations cannot be objectively verified, compared, or composed. We introduce compositional interpretability, a category-theoretic framework grounded in the principles of compositionality and minimum description length. Compositional interpretations are pairs of syntactic and semantic mappings that must commute to enforce consistency between a model’s decomposition and its observed behaviour. We deconstruct explanation quality into measures of faithfulness and complexity to cast interpretability as a constrained optimisation problem, and introduce compressive refinement to systematically restructure models into simpler parts without altering their function. Finally, we prove a parsimony criterion under which syntactic compression theoretically guarantees more concise, human-aligned explanations. Our framework situates prominent mechanistic methods as subclasses of refinement, and clarifies why their compressibility heuristics tend to align with human interpretability. Our work provides a measurable, optimisable foundation for automating the discovery and evaluation of mechanistic explanations.
@misc{gauderis_compositional_2026, title = {From Mechanistic to Compositional Interpretability}, author = {Gauderis, Ward and Dooms, Thomas and Holmer, Steven T. and Ayonrinde, Kola and Wiggins, Geraint A.}, year = {2026}, month = may, eprint = {2605.08934}, archiveprefix = {arXiv}, primaryclass = {cs.LG}, url = {https://arxiv.org/abs/2605.08934}, }
2025
- MI @ NeurIPS
 Finding Manifolds With Bilinear AutoencodersIn Mechanistic Interpretability Workshop: At the Thirty-Ninth Annual Conference on Neural Information Processing Systems, Oct 2025
Finding Manifolds With Bilinear AutoencodersIn Mechanistic Interpretability Workshop: At the Thirty-Ninth Annual Conference on Neural Information Processing Systems, Oct 2025Sparse autoencoders are a standard tool for uncovering interpretable latent representations in neural networks. Yet, their interpretation depends on the inputs, making their isolated study incomplete. Polynomials offer a solution; they serve as algebraic primitives that can be analysed without reference to input and can describe structures ranging from linear concepts to complicated manifolds. This work uses bilinear autoencoders to efficiently decompose representations into quadratic polynomials. We discuss improvements that induce importance ordering, clustering, and activation sparsity. This is an initial step toward nonlinear yet analysable latents through their algebraic properties.
@inproceedings{dooms_bilinear_2025, title = {Finding Manifolds With Bilinear Autoencoders}, url = {https://openreview.net/forum?id=ybJXIh4vcF}, urldate = {2025-10-13}, booktitle = {Mechanistic Interpretability Workshop: {At} the Thirty-Ninth Annual Conference on Neural Information Processing Systems}, author = {Dooms, Thomas and Gauderis, Ward}, month = oct, year = {2025}, }
2024
- Compositionality Unlocks Deep Interpretable ModelsIn Connecting Low-Rank Representations in AI: At the 39th Annual AAAI Conference on Artificial Intelligence, Nov 2024
We propose χ-net, an intrinsically interpretable architecture combining the compositional multilinear structure of tensor networks with the expressivity and efficiency of deep neural networks. χ-nets retain equal accuracy compared to their baseline counterparts. Our novel, efficient diagonalisation algorithm, ODT, reveals linear low-rank structure in a multilayer SVHN model. We leverage this toward formal weight-based interpretability and model compression.
@inproceedings{dooms_compositionality_2024, title = {Compositionality {Unlocks} {Deep} {Interpretable} {Models}}, url = {https://openreview.net/forum?id=bXAt5iZ69l}, urldate = {2025-02-17}, booktitle = {Connecting {Low}-{Rank} {Representations} in {AI}: {At} the 39th {Annual} {AAAI} {Conference} on {Artificial} {Intelligence}}, author = {Dooms, Thomas and Gauderis, Ward and Wiggins, Geraint and Oramas, Jose}, month = nov, year = {2024}, } - Bilinear MLPs Enable Weight-Based Mechanistic InterpretabilityIn The Thirteenth International Conference on Learning Representations, Oct 2024
A mechanistic understanding of how MLPs do computation in deep neural net- works remains elusive. Current interpretability work can extract features from hidden activations over an input dataset but generally cannot explain how MLP weights construct features. One challenge is that element-wise nonlinearities introduce higher-order interactions and make it difficult to trace computations through the MLP layer. In this paper, we analyze bilinear MLPs, a type of Gated Linear Unit (GLU) without any element-wise nonlinearity that neverthe- less achieves competitive performance. Bilinear MLPs can be fully expressed in terms of linear operations using a third-order tensor, allowing flexible analysis of the weights. Analyzing the spectra of bilinear MLP weights using eigendecom- position reveals interpretable low-rank structure across toy tasks, image classifi- cation, and language modeling. We use this understanding to craft adversarial examples, uncover overfitting, and identify small language model circuits directly from the weights alone. Our results demonstrate that bilinear layers serve as an interpretable drop-in replacement for current activation functions and that weight- based interpretability is viable for understanding deep-learning models.
@inproceedings{pearceBilinearMLPsEnable2024a, title = {Bilinear {{MLPs}} Enable Weight-Based Mechanistic Interpretability}, booktitle = {The {{Thirteenth International Conference}} on {{Learning Representations}}}, author = {Pearce, Michael T. and Dooms, Thomas and Rigg, Alice and Oramas, Jose and Sharkey, Lee}, year = {2024}, month = oct, urldate = {2025-05-07}, langid = {english}, url = {https://openreview.net/forum?id=gI0kPklUKS}, arxive = {2410.08417}, }